


Next: Datenbank-Abgleich
Up: Automatisierte Belegverarbeitung
Previous: Automatisierte Belegverarbeitung
Abbildung 5.1:
Schriftzug und Erkennungsergebnis
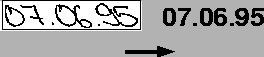 |
Der erste Schritt unserer Aktivitäten war die
Entwicklung von ,,COGNITUS``, einer Erkennungssoftware, die auf
leistungsfähigen hierarchischen
Nächste-Nachbar-Klassifikationsverfahren basiert. Diese erlauben es,
eine große Vielfalt von Schriftarten abzudecken und sehr niedrige
Fehlerraten zu erzielen. In einfachen Fällen wird dabei eine
Klassifikation durch Vergleich des zu lesenden Zeichens mit
einigen wenigen Prototypen vorgenommen, während nur in
Zweifelsfällen aufwendigere Operationen eingesetzt werden, um ein
höchstes Maß an Sicherheit zu garantieren. Auf diese Weise
können etwa 350 Ziffern pro Sekunde bei einer Fehlerrate von nur
0.5% erkannt werden. In enger Zusammenarbeit zwischen der
Segmentierungs-, Klassifizierungs- und Kontextkorrektureinheit wird
anschließend die global wahrscheinlichste Interpretation
ermittelt, wodurch eine sehr hohe Zuverlässigkeit erreicht wird.
Das Programm wurde zunächst zur Erfassung hand- und
maschinengeschriebener Überweisungsformulare entwickelt, ist jedoch
leicht vom Benutzer auf andere Anwendungen anpaßbar. Durch eine
effiziente Implementierung wird eine hohe Verarbeitungsleistung von
etwa fünf Formularen pro Sekunde auf einem Pentium Prozessor
erreicht. Für noch höhere Leistungsanforderungen ist der Einsatz
von Parallelrechnern problemlos möglich. Die Entwicklung von
,,COGNITUS`` ist weitgehend abgeschlossen.
Abbildung 5.2:
Ergebnis des Skelettierungsverfahrens
 |
Im Rahmen dieser Entwicklung ist an unserem Lehrstuhl im
Berichtszeitraum eine Promotionsarbeit angefertigt worden, die sich auf
das Teilproblem der dynamischen Segmentierung konzentriert. Hier geht
es um die Aufteilung des Dokumentes in einzelne Zeichen. Sie stellt
ein grundlegendes Problem bei der Handschriftenerkennung dar. Reicht
es bei Maschinenschriften noch aus, das Bild in
Zusammenhangskomponenten aufzulösen und lediglich in einigen Fällen
sich berührende Zeichen durch eine senkrechte Linie zu trennen, so
ist die Situation bei Handschriften im Normalfall viel komplizierter.
Es ist nötig, zuerst die morphologische Grundstruktur der Zeichen zu
erfassen. Dazu wurde eine neues Skelettierungsverfahren entwickelt,
das gegenüber Rauschen sehr robust ist und an die Auflösung der
Zeichen angepasst werden kann. Skelettierungsverfahren reduzieren die
Zeichen zunächst auf Linien von einem Pixel Breite. Danach zerlegt
man die Zeichenfolgen in ihre topologischen Bestandteile
(d. h. die einzelnen Linienstücke). Der darauf folgende Schritt des
Schrifterkennungsverfahrens fügt nun diese elementaren Bestandteile
zu Gruppen zusammen, die jeweils einem Buchstaben entsprechen. In
vielen Fällen müssen dabei mehrere Möglichkeiten der Gruppierung
generiert und anschließend mit dem Buchstabenerkenner ausgewertet
werden, um die beste Zerlegung zu ermitteln. Dies stellt sicher, daß
auch Zeichen, die sich überlappen, noch richtig erkannt werden, und
damit ein optimales Erkennungsergebnis erreicht wird.
Abbildung 5.3:
Rekombinationsmöglichkeiten des Monatsfeldes aus Bild (5.1)
 |
Next: Datenbank-Abgleich
Up: Automatisierte Belegverarbeitung
Previous: Automatisierte Belegverarbeitung
Webmaster<www@zpr.uni-koeln.de>
1999-07-28